

Key Takeaways
- Models perform best well before their maximum context window capacity
- Every token in context actively shapes output through attention mechanisms
- LLMs are stateless; nothing persists between turns without explicit re-injection
- Information at the start or end is retrieved better than middle content
- Models treat all context as equally valid unless externally verified
Context engineering is the practice of managing what information AI models process to maximize output quality and minimize hallucinations. Unlike prompt engineering (how you ask), context engineering determines what the AI "sees" and "remembers."
I spent the past month at Juma fixing hallucinations and output quality issues by applying first principles to context management. Below are the five fundamental axioms that transformed our approach, whether you're having individual AI conversations, building marketing workflows, or developing autonomous agents.
What is Context Engineering?
Context engineering is the systematic design of information that AI models process to generate responses. It addresses what data the model accesses, how that data is structured, when information persists across conversations, and how to prevent errors from propagating through future outputs.
Context engineering involves four core activities: curating relevant information, structuring data for optimal retrieval, managing persistence across sessions, and validating outputs before they enter context. For teams building AI agents or marketing workflows, context engineering separates demos from production systems.
Axiom 1: Context is Limited
Models perform best well before their advertised maximum context window because attention mechanisms spread focus across all tokens, creating diminishing returns that degrade output quality as you approach capacity limits. The model's attention operates with a fixed budget, and every piece of information you add competes for that budget.
This creates the "lost in the middle" phenomenon where information buried in the center of long contexts is retrieved less reliably. Past a certain threshold, more context actually produces worse output because the signal gets lost.
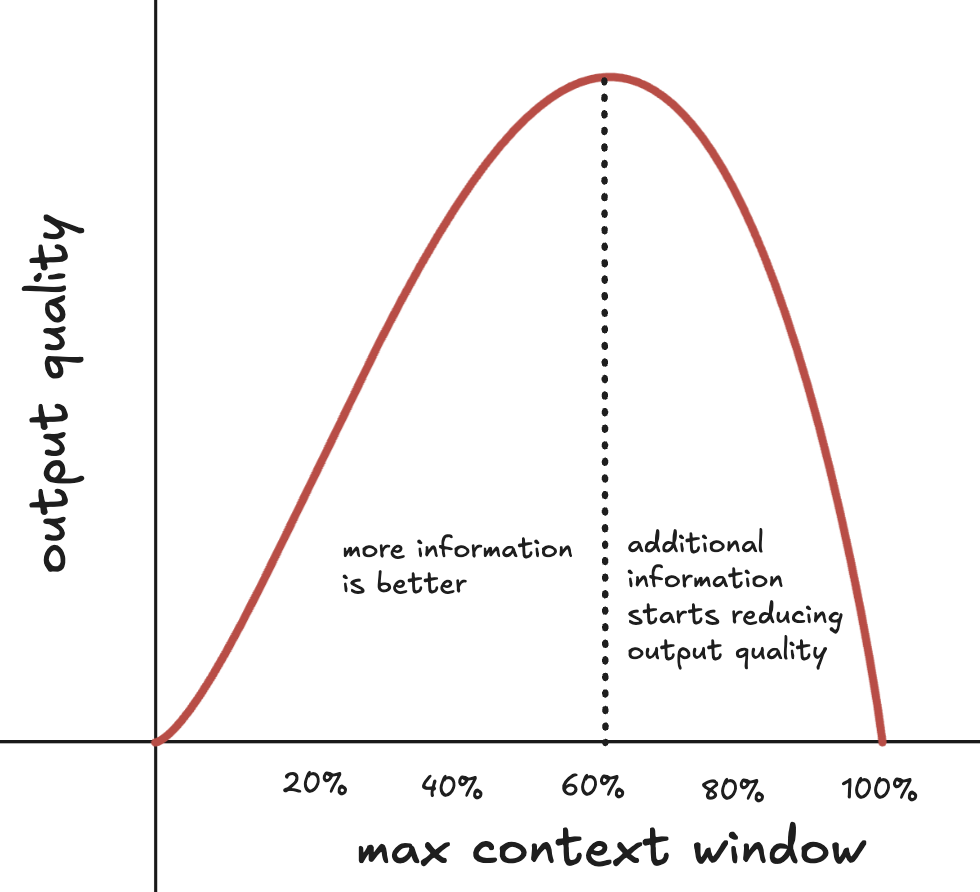
Even though model providers advertise their maximum context windows - Opus 4.5 at 200k tokens and GPT-5.2 at 400k - performance starts degrading well before you hit those limits.
As context length increases, performance degrades between 14% to 85% even when models could perfectly retrieve all relevant information.
How to Apply
Work on one task per chat. If the chat gets long, ask the AI to summarize it, then start over in a new chat. In Claude Code you can use /compact when you approach around 60% of the maximum context window.
Edit instead of adding. When you don't like an output, go back and edit your original message instead of sending a new message with more instructions. This saves one turn of output, reasoning, and metadata tokens while keeping the context small.
Audit everything. If you're building agents, be critical of everything you put in context, especially the tool instructions, calls, and results. Make sure you have the minimum number of high signal tokens to help the AI perform the task at hand.
Axiom 2: Every Token Affects the Output
All information in context participates in output generation through attention mechanisms where every token gets weighted against every other token, meaning everything you include (instructions, examples, typos, formatting, metadata) actively shapes what the AI generates next. Think of it like a giant probability calculation where each piece of information in your context gets a vote on what comes next.
This creates non-obvious problems. When you give an AI multiple tasks with conflicting instructions, they're all actively competing for attention with each other. The end result is an inferior output on all tasks because the AI spreads thin across them.
In agentic systems, when you give an AI access to twenty different tools, it doesn't just "know they exist"; those tool definitions are actively competing with each other. We've seen models call completely irrelevant tools just because they were listed, even when the correct answer was "use no tools at all."
Also, contrary to popular belief, telling the model to "act as a developer" has no statistically significant effect on performance. When there's an effect in performance, it's often negative. The issue is that these role-playing tokens don't unlock "hidden capabilities" and just shift the model's probability distribution in unpredictable ways. The same goes for verbose prompts copied from the web, with instructions like "be creative," "think step by step," or "be concise but thorough."
How to Apply
Treat every word like it costs something. Before adding anything to context, ask "is this directly useful for the specific task at hand?"
Remove redundant definitions. When we removed redundant tool definitions and streamlined our system prompts at Juma, we saw fewer hallucinations and more focused responses.
If you want something to have zero influence on the output, don't put it in the context at all. This means being pedantic in scrutinizing what you include.
Example: Minimize tool definitions
Instead of listing every available tool, provide only what's needed for the current task:
❌ Before: 20 tools listed (web_search, calculator, email_sender, calendar, file_reader, code_executor...)
✅ After: 3 relevant tools (web_search, calculator, email_sender)
The same principle applies to brand voice. Extract high-signal patterns instead of injecting verbose style guides.
Axiom 3: Nothing Persists Between Calls
LLMs are completely stateless, meaning between chat turns or API calls nothing persists (no conversation history, no learned preferences, no accumulated understanding), so every message you send arrives as if the model is seeing it for the first time. What the model actually sees is something like: "based on this conversation history, how would you respond?"
To combat this stateless feeling, ChatGPT's memory system uses explicit memory layers like session metadata, stored user facts, conversation summaries, current messages which are all injected into every request. The user is left with the feeling that "the model remembers" but in reality it's the developer who remembers to re-inject memory context into the chat.
Great context is an engineering challenge, not a model capability. If you want the AI to "remember" something, explicitly persist it and re-inject it into context at the right time. This is where most of the competition exists nowadays for good chat UX.
How Juma Solves This
This is exactly why we built Juma Projects. Projects act as persistent context containers where your team's knowledge, brand voice, and conversation history are automatically maintained and re-injected when needed.
Instead of manually copying and pasting context between conversations or losing critical information when you start a new chat, Projects ensure that your AI assistant always has access to the right context without hitting token limits or degrading performance.
Axiom 4: Position Affects Attention
Information's influence varies by position within context because models retrieve information placed in the middle of long contexts less reliably than information at the beginning or end, a phenomenon where position accuracy tests show unique words near the beginning are identified correctly more often than words in the middle. This is the "lost in the middle" phenomenon.
Manus exploits this deliberately. Their agent constantly rewrites a todo.md file, pushing task objectives to the end of context where attention is strongest. They call it "manipulating attention through recitation."
How to Apply
Be mindful of where you're pasting large chunks of text. Structure your prompts by placing core instructions either at the start or end, with additional context in between.
Use role-based prompting. Models treat instructions of type role:system with higher priority than of role:user. Always make sure your system prompt has a proper role set and is placed at the beginning of the conversation sequence.
Example structure:
[START - System Role]
Brand Voice: Professional, conversational, helpful
Forbidden: Jargon, exclamation points, passive voice
[MIDDLE - Reference]
Product features: [documentation]
Past campaigns: [examples]
[END - Task]
Write a LinkedIn post about our new AI feature.
Axiom 5: Context is Not Self-Correcting
Models treat all information in context as equally valid premises (trusted documents, user typos, and hallucinations from previous turns all carry equal weight) because from the model's perspective context is a set of premises that it cannot distinguish as correct or incorrect without external verification. The model doesn't "know" which parts of context are accurate.
This is why context poisoning is so dangerous. Once an incorrect assumption enters the context, the model does not treat it as suspicious or provisional. It will produce logically consistent, well-structured answers built entirely on false premises.
Summarization and tool outputs make this worse. When you summarize a conversation and inject it back into context, any errors in that summary become the new ground truth. The model can't "remember" that this information was lossy or uncertain; from its perspective, the summary is just as trustworthy as the original, often more so because it's newer.
The same applies to agentic systems that persist tool outputs, failed attempts, or scratchpad notes. If a tool returns misleading data and you persist it in context, the agent will happily build future decisions on top of it. Manus explicitly calls this out in their agent design: context must be curated, not trusted by default.
How to Apply
When chatting, if the AI makes a mistake, correct it explicitly. Don't assume it will self-correct. The model treats its own previous outputs as valid premises unless you tell it otherwise.
If you notice the conversation going off track, either correct it directly ("you're wrong; here's what I meant") or start a new chat. Don't let errors accumulate.
If you're building agents, persist errors and failures in context rather than cleaning them up. When an agent sees its own failed actions and stack traces, it becomes less likely to repeat the same mistake. However, there's a critical distinction: persist the evidence of failure (the action that didn't work, the error message) but don't persist incorrect information stated as fact. The key is distinguishing between "I tried this and it failed" (valuable learning signal) versus "this incorrect thing is true" (context poisoning).
Common Context Engineering Mistakes
Based on our experience at Juma, here are the most frequent errors:
1. The "Dump Everything" Trap
Mistake: Adding all available documentation to context without curation. More information doesn't mean better results; it means diluted attention and degraded performance.
Fix: Curate context based on the specific task. Ask "does this piece of information directly contribute to the current objective?"
2. Ignoring Position Effects
Mistake: Placing critical instructions in the middle of long prompts where they're most likely to be "lost in the middle."
Fix: Put your most important instructions at the beginning or end of your context. Use system prompts for critical, unchanging instructions.
3. Assuming Persistence
Mistake: Expecting the model to "remember" from previous sessions without explicitly re-injecting that information.
Fix: Use tools that automatically manage context persistence, or manually track what needs to be re-injected between sessions.
4. No Error Handling
Mistake: Not validating or fact-checking AI outputs before they enter context for future turns.
Fix: Implement verification steps. If you're building AI agents, add human-in-the-loop checkpoints for high-stakes decisions.
5. Conflicting Instructions
Mistake: Giving multiple tasks with competing objectives in one prompt, forcing the model to spread attention across conflicting goals.
Fix: One task per conversation. If you need multiple outputs, break them into sequential steps or separate chats.
When to Use Context Engineering
Not every problem requires context engineering. Here's when to use different approaches:
Frequently Asked Questions
What is the difference between context engineering and prompt engineering?
Prompt engineering focuses on how you phrase requests to AI models, while context engineering determines what information the AI has access to throughout the conversation. Prompt engineering is about crafting better instructions; context engineering is about managing the entire information architecture that shapes AI output quality and reliability.
Why does AI performance degrade with more context?
AI models use attention mechanisms with a fixed budget of focus. When you add more information to context, the model must spread its attention across all tokens, creating diminishing returns. Past a certain threshold, additional context dilutes focus on critical information, causing the "lost in the middle" phenomenon where retrieval accuracy drops significantly.
How do I know when my context is too large?
Watch for these signs: the AI starts ignoring instructions, responses become less focused, hallucinations increase, or the model fails to retrieve information you know is in the context. As a rule of thumb, aim to use around 60% of the maximum context window before summarizing and starting fresh.
Can AI models remember information from previous conversations?
No. LLMs are completely stateless and retain nothing between turns. What appears as "memory" is actually systems that explicitly persist information and re-inject it into every new request. Tools like ChatGPT Memory and Juma Projects manage this persistence automatically, but the underlying model has no memory capability.
What is context poisoning and how do I prevent it?
Context poisoning occurs when incorrect information enters context and the model treats it as equally valid as correct information, building future outputs on false premises. Prevent it by explicitly correcting errors, validating AI outputs before they enter persistent context, using structured formats that make contradictions visible, and implementing approval workflows for critical information.
The Future of Context Engineering
Context engineering is evolving from implicit skill to explicit discipline. As context windows expand to millions of tokens, the challenge isn't capacity, it's curation.
The teams that will succeed with AI aren't those who can stuff the most information into context. They're the teams who understand these five axioms and build systems that respect the fundamental constraints of how LLMs process information.
At Juma, we're building tools that make context engineering accessible to marketing teams who don't have ML backgrounds. Because ultimately, context engineering shouldn't require a PhD; it should be as intuitive as organizing your files or structuring a document.
The five axioms are your foundation. Everything else is implementation details.
1 workspace
20 messages total
Shared Projects only
1 workspace
50 messages total
Unlimited private & shared Projects
1 workspace
Unlimited messages
Unlimited private & shared Projects
Unlimited workspaces
Unlimited messages
Unlimited private & shared Projects
1 workspace
20 messages total
Shared Projects only
1 workspace
50 messages total
Unlimited private & shared Projects
1 workspace
Unlimited messages
Unlimited private & shared Projects
Unlimited workspaces
Unlimited messages
Unlimited private & shared Projects